
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
智能开放搜索 OpenSearch行业算法版,1GB 20LCU 1个月
本文系统对比了扩散模型与Flow Matching两种生成模型技术。扩散模型通过逐步添加噪声再逆转过程生成数据,类比为沙堡的侵蚀与重建;Flow Matching构建分布间连续路径的速度场,如同矢量导航系统。两者在数学原理、训练动态及应用上各有优劣:扩散模型适合复杂数据,Flow Matching采样效率更高。文章结合实例解析两者的差异与联系,并探讨其在图像、音频等领域的实际应用,为生成建模提供了全面视角。
生成模型已成为人工智能领域的关键突破,赋予机器创建高度逼真的图像、音频和文本的能力。在众多生成技术中,扩散模型和Flow Matching尤为引人注目。这两种方法虽然都致力于在噪声与结构化数据之间建立转换,但其基础原理存在本质区别。本文将系统地比较这两种先进技术,深入探讨其数学原理、实际应用及理论解释。
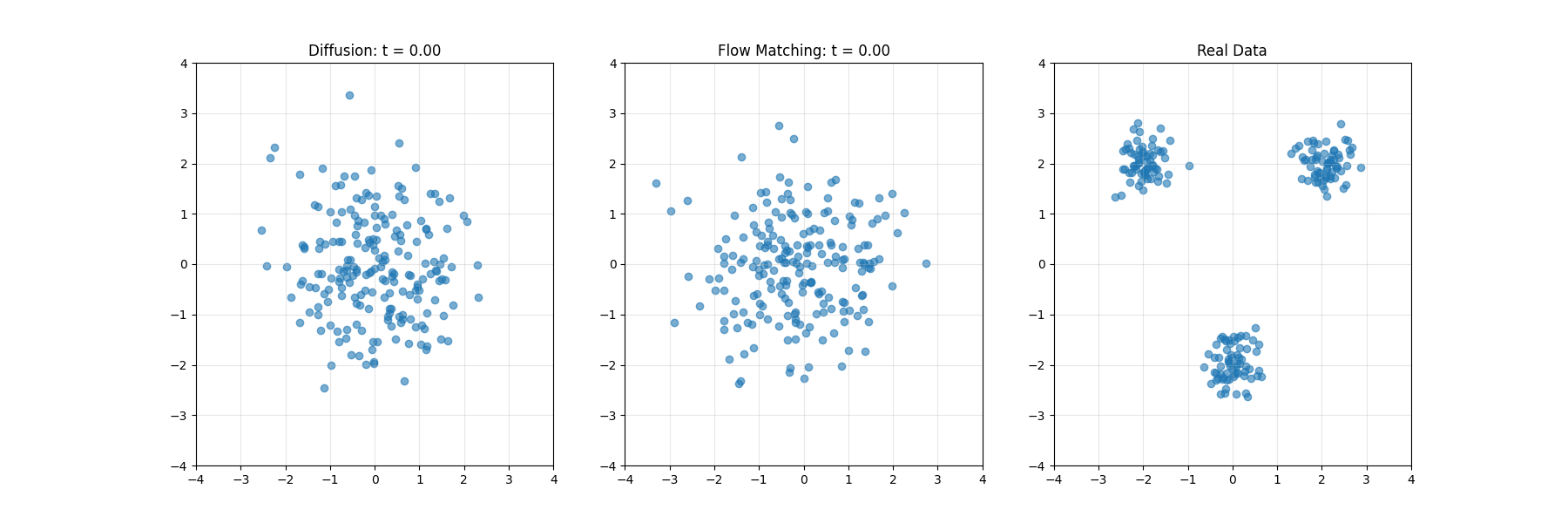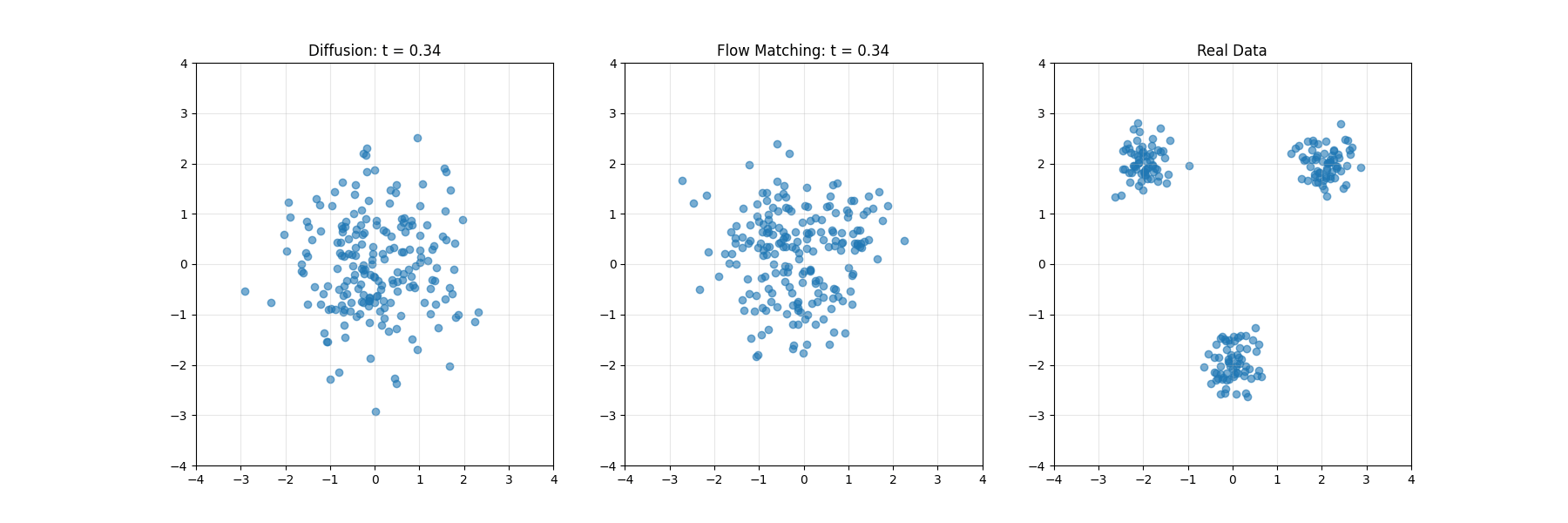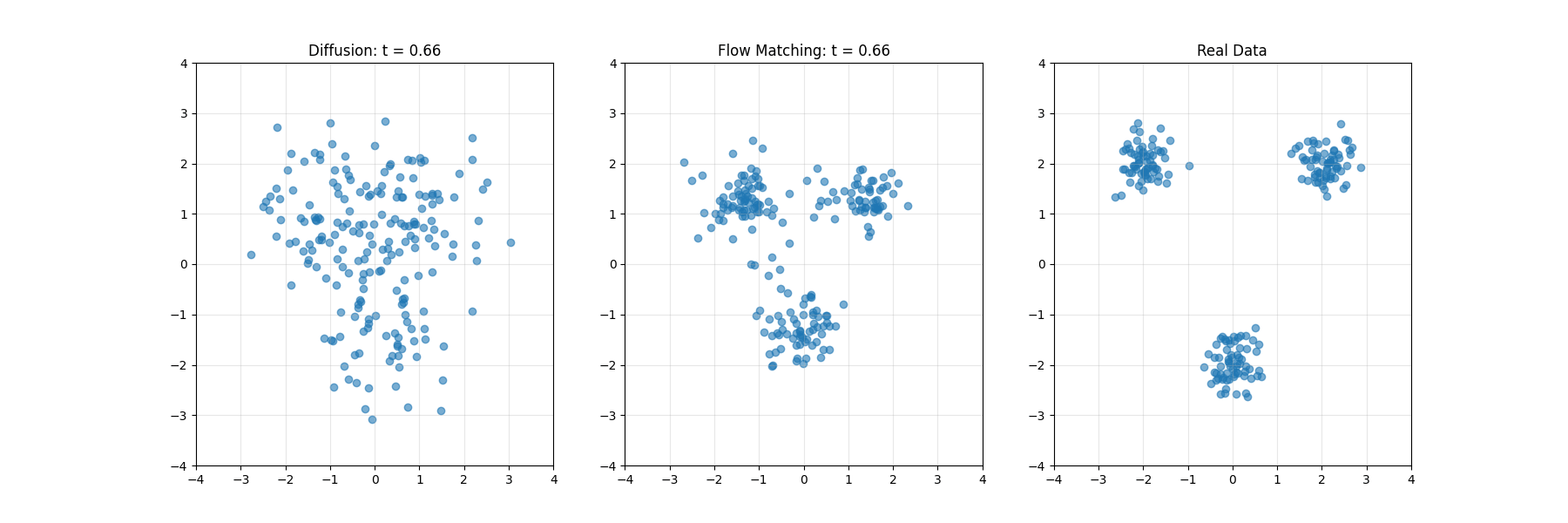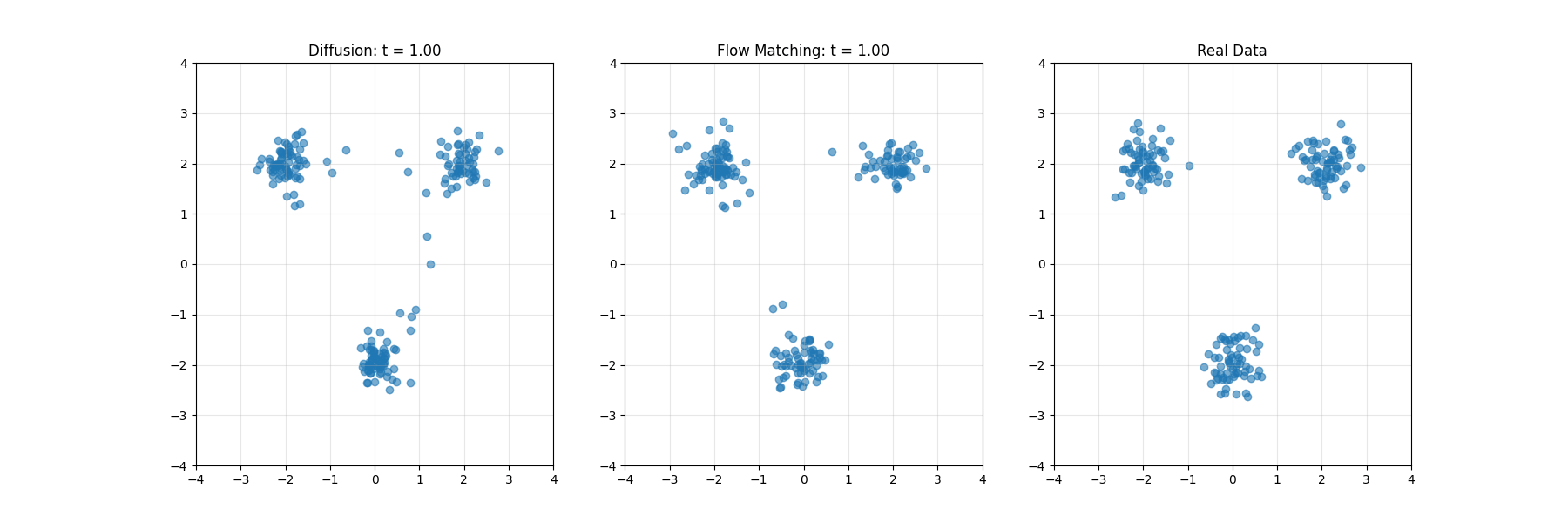
扩散模型系统性地向数据添加噪声,直至将其转化为纯粹的随机噪声,然后学习此过程的逆向转换。这一过程可类比为将照片逐步溶解至完全模糊状态,随后从模糊中重建原始影像的过程。
Flow Matching则构建噪声分布与数据分布间的连续路径(流)。这一过程可类比为定义一种平滑的转换计划,使随机噪声逐渐形成有结构的数据,如同观察一块黏土从无序状态被塑造成精细雕像的过程。
扩散模型定义了一个前向过程,该过程在 $T$ 个时间步长内有序地向数据 $x_0$ 添加高斯噪声:
其中 $W_t$ 代表标准维纳过程(布朗运动),$f(x_t, t)$ 为漂移系数,$g(t)$ 为扩散系数。
经过充分的扩散步骤,$x_T$ 将近似标准正态分布 $\mathcal{N}(0, I)$,原始数据的结构信息基本完全消散。
扩散模型的核心在于学习逆转噪声添加过程,通过从随机噪声开始并迭代去噪来生成新数据。
Flow Matching建立在连续归一化流(CNF)的理论之上,CNF通过微分方程将一个概率分布转换为另一个:

速度场是一个为时空中每个点分配速度向量的函数,可类比为风向图,指示了粒子在任一位置应移动的方向与速度。在生成模型语境下:

物理理解:可想象为河流中任一点的水流方向与强度,决定了漂浮物体的运动轨迹。
变换特性:通过从 $t=0$ 到 $t=1$ 追踪速度场,可以得到样本从源分布(通常为噪声)到目标数据分布的转换路径。
在Flow Matching中,通过神经网络学习预测给定位置和时间的速度向量,该网络经训练以匹配定义分布间所需流的参考向量场。

Flow Matching的关键创新在于直接监督速度场 $v_\theta$,利用预定义的分布间路径。此方法避开了从复杂的概率流方程推导速度场,而是直接约束速度场匹配参考向量场 $u(x,t)$,后者定义了样本的移动方式:

条件Flow Matching (CFM)作为重要扩展,构建了各数据点与噪声样本间的路径:
扩散模型通过添加高斯噪声定义固定的随机路径。前向过程由预设的噪声调度确定,模型学习逆转这一特定过程。
Flow Matching则允许在分布间设计灵活路径。这些路径可为直线、曲线轨迹,甚至可动态学习,提供更大的设计自由度。
扩散模型通常需要估计复杂的概率密度或其替代量,导致训练过程更具挑战性,且对噪声调度的精确设计有较高依赖。
Flow Matching直接监督速度场,形成更简洁的均方误差目标,训练过程通常更为稳定。
扩散模型传统上需要较多采样步骤(通常1000步以上),尽管DDIM等技术已有所改进。
Flow Matching通常可利用高阶ODE求解器,以较少步骤(10-100步)实现高质量采样。
Flow Matching在特定条件下对精确密度匹配提供保证,为优化概率流ODE提供更直接路径。
扩散模型可类比为海滩上沙堡的侵蚀与重建。前向过程如同潮水逐渐冲刷沙堡,直至形成平坦沙面;反向过程则是学习如何通过理解沙粒运动规律,从平坦沙面重建精细结构。
Flow Matching类似于空间导航系统,在任一位置提供指向目标的方向矢量。无需遵循预设路线,学习的矢量场能从任意起点引导系统抵达目标分布。
扩散模型在采样过程中通常需要更多的函数评估,导致计算成本相对较高。然而,这类模型可以使用相对简化的架构和损失函数进行训练,在实现复杂度方面具有一定优势。
Flow Matching则通过采用复杂的ODE求解器实现更高的采样效率,但精确建模速度场可能需要更为复杂的网络架构设计。两种方法的计算效率取舍主要体现在采样速度与模型复杂度之间的平衡。
两种方法均能达到先进的样本生成质量,选择应基于具体应用需求进行评估。扩散模型在处理高度结构化数据(如高分辨率图像和复杂音频)方面表现出色;而Flow Matching则在处理相对简单的分布或对采样速度有严格要求的场景中展现出明显优势。实际应用中,需权衡模型复杂度、训练稳定性、采样效率及质量要求等多方面因素。
扩散模型与Flow Matching代表了生成建模领域的两类重要技术范式,各自基于独特的数学原理与实现策略。扩散模型通过定义固定的随机过程并学习其逆转,而Flow Matching则直接学习能够沿灵活路径转换分布的速度场。从某种意义上说,Flow Matching保留了扩散模型的核心优势,同时通过消除前向噪声过程的限制实现了技术简化。
深入理解这两种方法间的差异与联系,不仅有助于更全面把握生成建模的技术全貌,也为这一快速演进领域的发展提供了理论基础和研究方向。

三桥君深入解析企业AI Agent技术架构,涵盖语音识别、意图理解、知识库协同、语音合成等核心模块,探讨如何实现业务闭环与高效人机交互,助力企业智能化升级。
Confidential AI 实践:基于 Anolis OS 部署 Intel TDX 保护的 Qwen 模型
智谱AI发布新版VLM开源模型GLM-4.1V-9B-Thinking,引入思考范式,性能提升8倍
VTJ平台提供开发工具与扩展框架,支持低代码应用的开发与拓展。包含CLI、插件系统及Uni-App集成,结合Vite、TypeScript和Vue优化开发流程。
AI量化交易融合人工智能与量化分析,通过算法模型深度解析市场数据,自动生成并执行交易策略,显著提升交易效率与决策精准度。其开发涵盖目标分析、数据处理、算法设计、系统构建、测试优化、合规安全及持续迭代等多个关键环节,涉及金融、编程、大数据与AI等多领域技术。掌握这些核心技术,方能打造高效智能的量化交易系统,助力投资者实现更优收益。
16个AI Logo 设计工具大盘点:技术解析、Logo格式对比与实用推荐
本文介绍了品牌标志(Logo)的重要性,并盘点了多款免费且好用的 Logo 生成工具,分析其输出尺寸、格式及适用场景,帮助无设计基础的用户选择合适工具,高效制作满足不同用途的 Logo。
在AI应用中Prompt撰写重要却难掌握,‘理解模型与行业知识是关键’:提升迫在眉睫
本文三桥君探讨Prompt优化技巧对AI应用的重要性。内容涵盖理解大语言模型、行业Know-how及Prompt撰写方法,助力提升AI输出质量与应用效率。
AI时代,Apipost和Apifox如何利用AI技术赋能API研发测试管理所需?
在数字化转型加速背景下,API成为企业互联互通的关键。Apipost与Apifox作为主流工具,在AI赋能方面差异显著。Apipost通过智能参数命名、接口设计自动化、测试用例生成、断言自动化等功能大幅提升研发效率和质量,尤其适合中大型企业及复杂业务场景。相比之下,Apifox功能依赖手动操作较多,适用性更偏向初创或小型项目。随着AI技术发展,Apipost展现出更强的智能化与前瞻性优势,为企业提供高效、稳定的API管理解决方案,助力其在竞争激烈的市场中实现创新突破。
Java 大视界 --Java 大数据在智慧交通公交车辆调度与乘客需求匹配中的应用创新(206)
Java 大视界 -- Java 大数据机器学习模型在自然语言处理中的对抗训练与鲁棒性提升(205)
使用 BAML 模糊解析改进 LangChain 知识图谱提取:成功率从25%提升到99%
【跨国数仓迁移最佳实践2】MaxCompute SQL执行引擎对复杂类型处理全面重构,保障客户从BigQuery平滑迁移
【新模型速递】PAI-Model Gallery云上一键部署Kimi K2模型
WebAssembly 与 Java 结合的跨语言协作方案及性能提升策略研究
WebAssembly 与 Java 结合实操指南 基于最新工具链的跨语言开发实践教程